

facecar全球顶尖的智能驾舱解决方案提供商,为了推动智能汽车科技的发展,普及更多的前沿驾舱黑科技技术,酝酿已久的“facecar智车微课堂”终于要和大家见面啦!
facecar特邀一批前瞻性技术专家,在线为大家准备了AR HUD,全息影像,智能车窗,眼球追踪,语音识别,远程召唤,手势交互,情绪识别,智能家居联动,盲点检测,自动泊车等一系列课程。
本期微课堂为您免费精彩呈现《车载语音黑科技,颠覆驾舱新体验》

汽车智能化以后,各大整车厂商越来越关注如何把人工智能技术和驾舱黑科技应用到驾舱里,更多的人开始对这些前沿的智能座舱技术想有更深的认知和了解,本文从语音识别原理、车载语音交互方案和语音车联网的研究专题几个方面,给大家做个专题分享。
丨语音识别原理
首先介绍一下语言识别的原理,语音识别由四个部分组成,一是解码器,二是声学模型,三是语言模型,最后就是特征提取的一个过程。
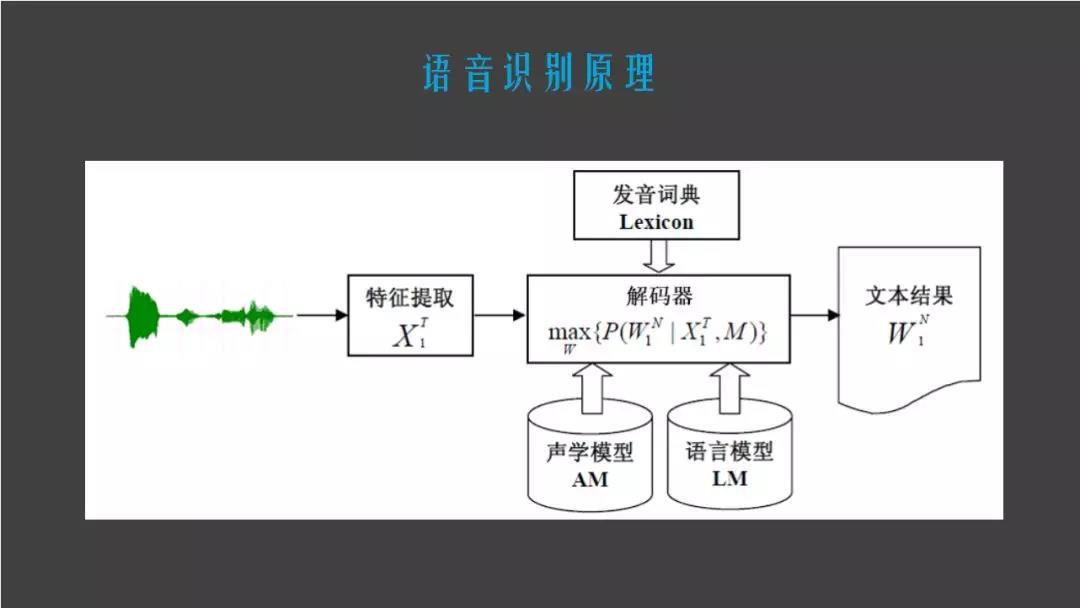
语音识别是如何实现的呢?首先一段声音进入之后,语音识别系统会做声音的特征提取,把一段声音分成一帧一帧的状态,几个状态组成一个因素,这个因素就是声学模型。举个例子,我要去天安门,这个“我”其实被拆分成很多帧,几帧组成一个状态,这个状态翻译成“我”这个拼音,这就是声学模型转移的过程。
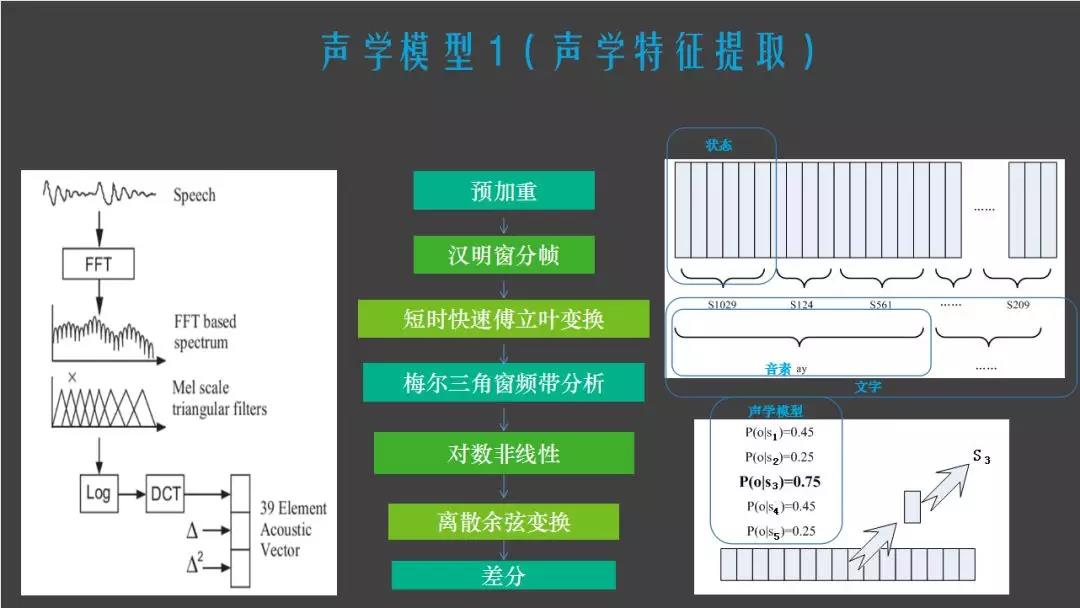
声学模型就是把刚刚转成的因素,比如“你现在在干什么”,通过声学模型转成拼音,但是哪个“你”,哪个“现”,哪个“在”,是由语言模型来控制的,下图中可以看出“你现在在干什么”有很多不同的路线,每个路线都有不同的概率,这个是通过模型训练出来的,算出一个总的概率,取一个概率最高的路线,就是机器会显示的结果。

丨车载语音交互方案
车里的语音方案,第一步不管做语音识别还是采集都是麦克风,现在如果在车里有两个麦克风,就可以做左边或右边的声学定位,声学定位的功能是什么呢?比如在车里我要说一句话,比如说“我要开窗”,但是其实你不知道它要开哪个窗,但是车里如果三到四个麦克风就可以做空间的立体定位,它会做一个区分,开对应的窗户。
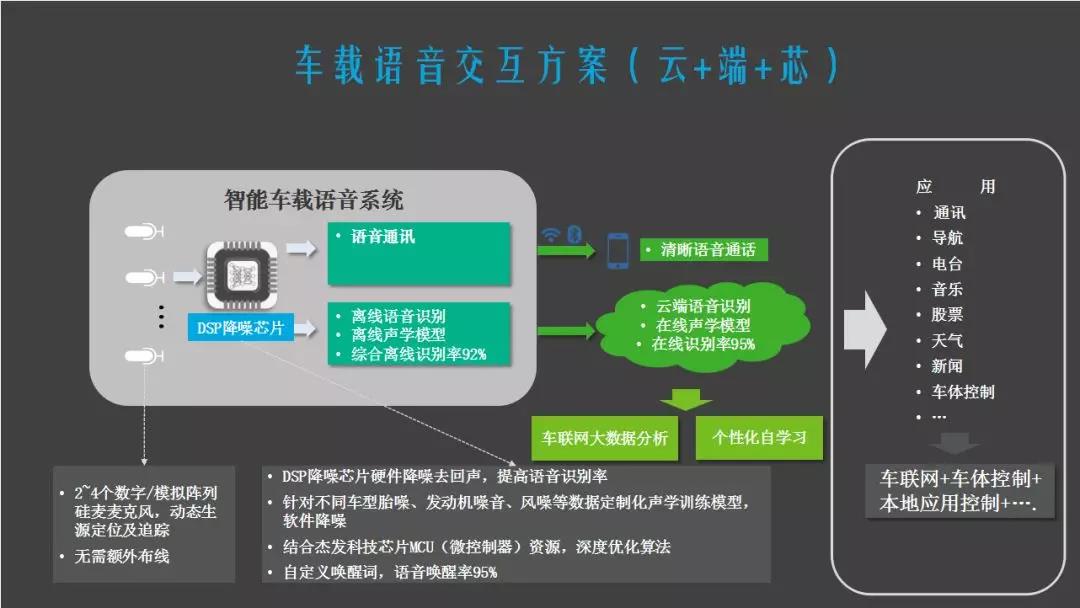
麦克风采集完成之后就是做降噪,车内并不是很好的语音识别的环境,必须要做一个降噪芯片,主要功能是降噪和去回声,降噪就是把胎噪,发动机噪声,风噪,空调噪音以及其它一些路面的噪音消除。对于这些比较稳态的噪音,用一个降噪芯片就可以把这些噪音全部消除。
降噪之后就是去回声,不管是打电话还是做语音识别都需要去回声的功能,因为打电话的时候会听到对面说的话,不做去回声会被收录进麦克风。给喇叭的同时会给去回声芯片一段声音,当它比对这两段声音一样,就不会收录进麦克风,这就是去回声的功能。
当声音进入之后就可以做语音识别的动作,语音识别分两块,离线的语音识别和在线的语音识别,目前汽车联网率并不高,但肯定比离线要准,离线是把语言模型和声学模型放到本地去做,而车机本身的配置是受到局限的,不能把太多东西放到本地,所以在云端的配置肯定要高很多,服务器配置肯定比本地的高很多,这时候就需要加一个判断模块,能联网的时候自动走云端,不能联网的时候走本地。
丨语音车联网研究专题
现在车企需要的是一整套车联网服务,单独的语音识别已经满足不了整车厂的需求了,因此后台需要集成各种内容,像电台,网络音乐,股票,天气等都已经做到了云端,提供整套车联网服务,下面就几个专题逐一进行分析。
1、实时+后台数据分析

第一部分,对后台的语音数据如何分析?现在在量产的项目中,大多是在云端的,不管车机是通过4G,WiFi还是Tbox联网,车机都是有联网能力的,一些联网的车机用户在用语音识别时,数据都会传到云端,这部分云端数据怎么用,目前大家都在讨论,这个可以通过用户的数据建一个平台,实现到不同的项目不同用户的数据,有了这些数据之后就可以做一个简单用户画像,比如有的人喜欢听音乐,有的人经常导航去户外,之后车厂做营销的时候这部份数据会是比较好的参考。
语音数据分析在汽车行业做得比较晚,在金融行业已经做了很多了,举个例子,大家都会经常接到推销保险的电话,而每个人接到的电话话术都是不一样的,因为我们基本上每个人在银行都有一个标签,他会基于历史的聊天记录去做一个判断,类似的事情,在车里也是可以这么去做的,因为车机以后也可能是个营销平台,它会去做一些后市场营销,比如卖正版音乐,卖耳机,卖保养,当我们知道用户在做什么的时候,给用户贴上一些标签,做一个变相的营销。
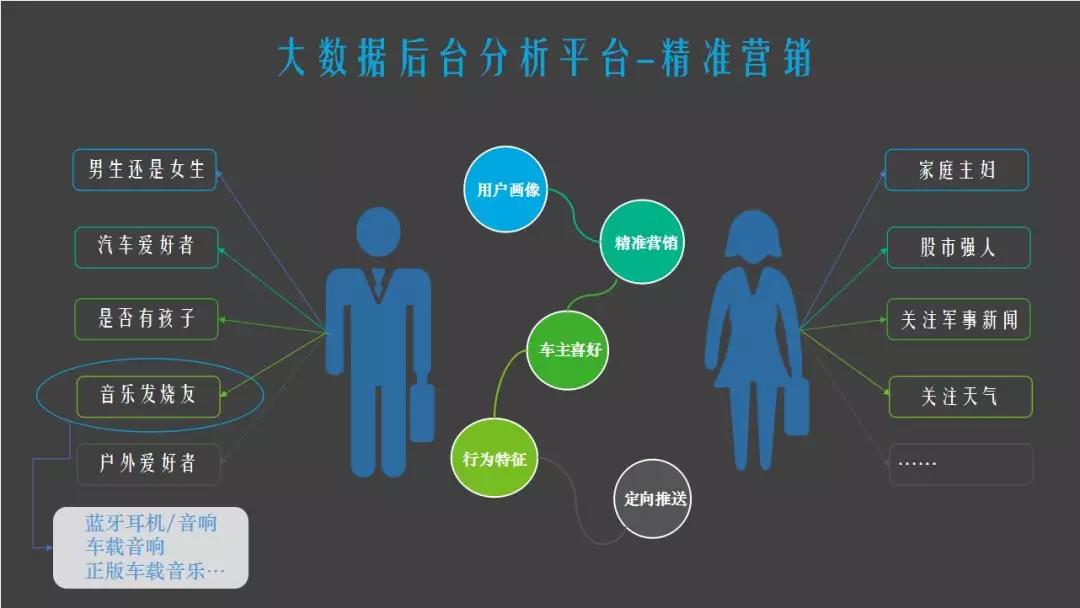
当然没有一家语音公司可以拿到每家车厂的用户数据,如果要做的话,这个数据一定要存在主机厂或tr1的内网上,去做绑定,没有用户数据绑定的数据是没有价值的。后装市场很多时候跟用户是绑定不上的,用户用了你的后装车机,但他不知道你是谁怎么联系,这个数据是没有价值的。但前装不一样,前装知道你这个人,知道车牌号,在什么位置,叫什么名字,这些是非常有价值的,都会发在车厂的内网上。
2、针对用户特征机器自学习
第二个专题就是机器自学习过程,这是比较接近人工智能的。 现在很多车厂都会对语音识别公司有一个要求,怎么让车机越用越准?不是通过升级的方式越用越准,而是通过机器自学的方式。
当一个用户在用一个车机时,用户的常用命令集不会超过一百条,这是在历史数据中分析出来的结果,这是怎么实现的呢?现在我们在后台给每个用户生成一个单独小模型,把用户常说的100句话或几十句话做一个保存,训练一个简单的声学和语言模型,在用户提出新的指令的时候两边一起走,一个是云端的大模型,一个是单独的小模型,他再说同样的话,小模型会比大模型要准,给用户的感觉就是越用越准,当用户总说这句话的时候,它会越来越精准。

3、针对声纹的技术应用
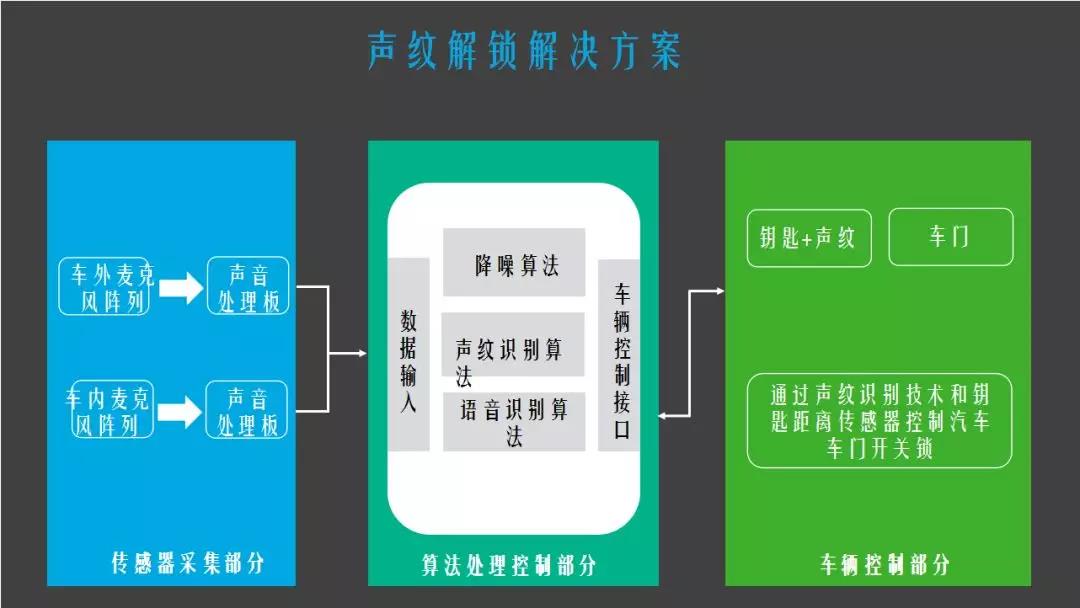
第三部分就是声纹的解决方案,目前声纹在车里也在做量产,但是效果没预期好,因为刚开始的想法是用声纹去解锁汽车,声纹对大家来说就是一个密码,生物密码,像指纹,视网膜,都是生物密码。在大家的想象中是跟电影里一样,车主跟车说开锁,车门啪就打开了,但去做了之后你会发现,车停的位置要么是车库要么是室外停车场,环境非常嘈杂,声纹对环境的要求还比较高,要保持相对安静,这种情况下去做,声纹的准确度不是很高。
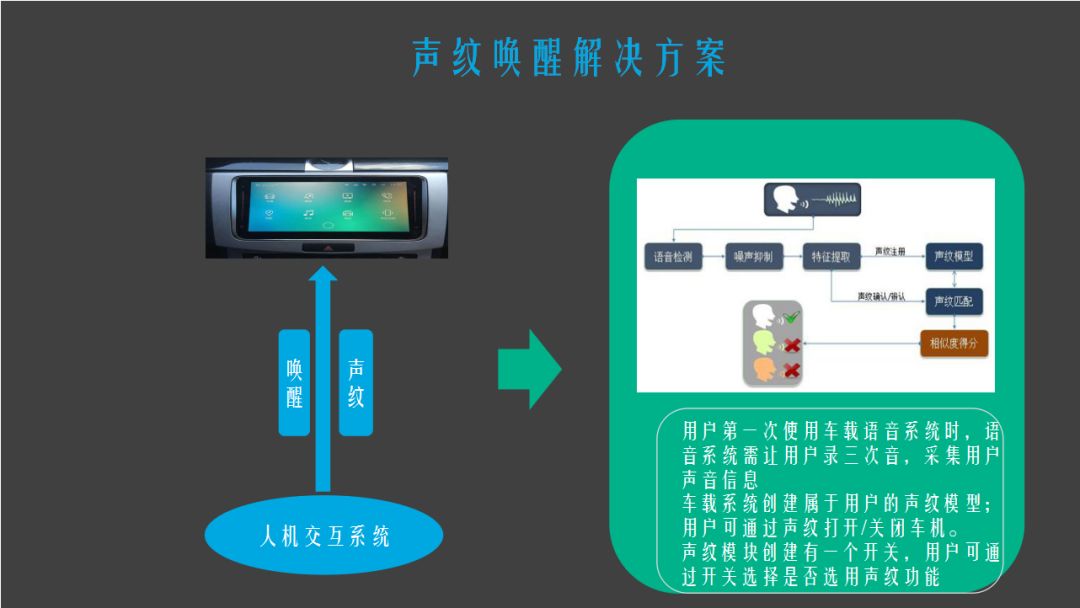
但是在另一个环境是可用的,就是在车里,这个其实在大家用微信的时候也用过这个功能,你需要先录一段声纹,然后可以用你的声纹去登陆微信,这个在车里也是一样的,车里有个功能叫语音唤醒,你跟它说一句你好XXX,它就会把语音界面调出来,就可以去使用一台车机。只有你这个人去说,它才能唤醒一台车机,这个是需要加一个模块的,在你第一次使用的时候要加一个声音采集的动作,会在本地有你的声纹特征,当你的声音匹配了之后,就可以去使用了,这个功能可以打开也可以关闭,关闭的时候所有人都可以去唤醒,打开的时候只有你自己可以唤醒,这个跟“hi siri”的原理是一样的。
4、汽车噪音环境的处理
最后一部分是声音的噪音环境处理,这个是现在大家都在研究的。第一个做法就是通过硬件的方式去做,主要是稳态的噪音可以通过这种方式去做,目前芯片在车机行业有个比较苛刻的认证就是carplay,是苹果发布的一个官方认证,对声音的要求是非常苛刻的,只有通过才能拿到苹果认证官方芯片,也就是苹果手机跟车机互联的一个功能。
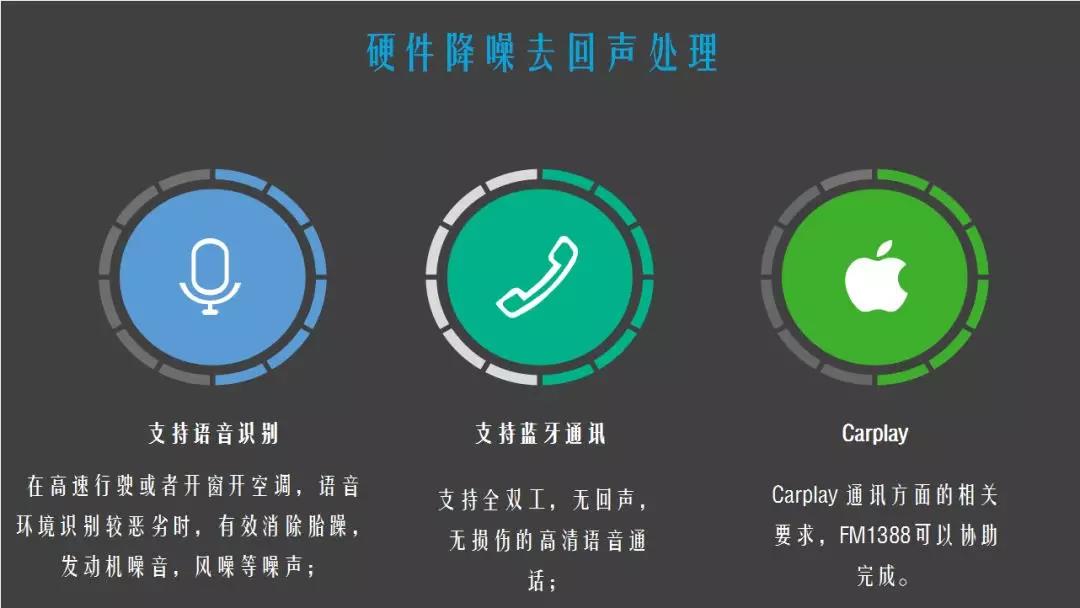
另外的一个做法是软件的去回声,每辆车的噪声有不同的差距,轿车SUV和商用车,每辆车一定是不一样的,每辆车在上线之前,都会采集一下这个汽车的声音,做一个专属声线模型,相当于把这个噪音训练给车机让它提前去适应这个噪音,当它以后在使用的过程中遇到这个噪音会把它默认当背景噪音,自动过滤,大约可以帮主机厂提升3个点识别率。

车载语音交互有着更安全和更方便的优势,有行业人士展望未来的车机内语音界面将替代图形界面,当车载语音系统可以真正解放双手,这个设想将迎来智能交通新一次的革命。目前,如何让智能语音交互系统真正实现情感化、智能化,语音理解和认知智能将成为新的着力点。

在微信中搜索faceui
或保存二维码在微信中打开




